
Duplicate Content (auf deutsch: „Doppelter Inhalt“ oder auch „Duplizierter Content“) ist ein häufiges Problem bei Webseiten und kann unter Umständen zu einem schlechteren Ranking bei Suchmaschinen (bspw. Google und Bing) führen – insbesondere durch eine mangelnde Indexierung von Seiten, die identischen oder weitestgehend ähnlichen Inhalt liefern.
Unter Duplicate Content versteht man identische oder sehr ähnliche Inhalte, die über unterschiedlichen URLs auffindbar sind. Man unterscheidet zwischen internem Duplicate Content (duplizierte Inhalte auf der eigenen Webseite) und externem Duplicate Content (meist Duplikate auf fremden Webseiten). Grundlage einer jeden OnPage Optimierung ist es, Duplicate Content ausfindig zu machen und bestmöglich zu vermeiden!
Inhaltsverzeichnis
- 1. Duplicate Content: Ursachen & Auswirkungen
- 2. Wie beeinflusst Duplicate Content das Ranking?
- 3. Was macht Google mit Duplicate Content?
- 4. Wie wird Duplicate Content von Google bewertet?
- 5. Häufige Ursachen für Duplicate Content
- 6. Duplicate Content Analyse
- 7. Duplicate Content vermeiden
- 8. Welche Seiten sollten nicht indexiert werden?
- 9. Was Sie nicht tun sollten, um Duplicate Content zu vermeiden
Duplicate Content: Ursachen & Auswirkungen
Fangen wir zunächst mit der häufigsten Fragestellung an: Was ist Duplicate Content? Unter „Duplicate Content“ oder auch „Doppeltem Inhalt“ versteht man gleiche oder sehr ähnliche Seiteninhalte, die über unterschiedliche URL’s auffindbar sind.
Dabei wird unterschieden zwischen:
- Interner Duplicate Content: Wenn derselbe Inhalt (bewusst oder unbewusst) über mehrere URL-Varianten einer Domain aufgerufen werden kann. Zum Beispiel auf Übersichtseiten für Tags, Filter und Kategorien, Paginationen, interne Suchergebnisseiten oder Beiträge und Seiten, die mehreren Kategorien zugeordnet sind.
- Externer Duplicate Content: Wenn derselbe Inhalt auf verschiedenen Domains zu finden ist, zum Beispiel auf unterschiedlichen (eigenen) Webprojekten oder auch Sprachversionen der eigenen Webseite. Auch die Verbreitung von Pressemitteilungen oder Plagiate durch Content-Diebstahl und Content-Scraping, die auf fremden Webseiten veröffentlicht wurden, können zu externem Duplicate Content führen.
Google ist zwar mittlerweile durchaus dazu in der Lage, Duplicate Content weitestgehend selbst zu erkennen und korrekt zu bewerten, dennoch ist es ratsam, doppelte Inhalte so gut es geht zu vermeiden und Google bei der Priorisierung der Inhalte zu unterstützen.
Wie beeinflusst Duplicate Content das Ranking?

Wenn Sie sich mit dem Thema Suchmaschinenoptimierung beschäftigen werden Sie sich zwangsläufig mit Duplicate Content auseinandersetzen. Die Suchmaschinen, allen voran Google, bevorzugen einzigartigen und qualitativ hochwertigen Content. An oberster Stelle steht der Suchende, der erwartet, dass er die bestmöglich passenden Suchtreffer zu seiner Anfrage gleich auf der ersten Seite erhält. Um diesem hohen Anspruch gerecht werden zu können, setzt Google erhebliche Ressourcen ein, um tagtäglich Millionen von Webseiten zu durchstöbern, zu analysieren, zu bewerten und zu indexieren. Wenn es nun mehrere Seiten gibt, die denselben oder beinahe identischen Inhalt ausliefern, dann kann nicht mehr eindeutig ermittelt werden, welche dieser Seiten die höchste Relevanz besitzt. In Folge dessen müssen sich die Seiten die Relevanz teilen, was sich negativ auf das Ranking auswirken kann. Im schlimmsten Fall werden Seiten gar nicht erst indexiert, da es bereits andere Seiten in Index gibt, die denselben Inhalt zur Verfügung stellen.
Je mehr Seiten von Duplicate Content betroffen sind, gesto gravierender können die Auswirkungen auf das Ranking sein. Insbesondere externer Duplicate Content kann zum Problem werden, wenn Google den Ursprung nicht mehr eindeutig feststellen kann.
Was macht Google mit Duplicate Content?
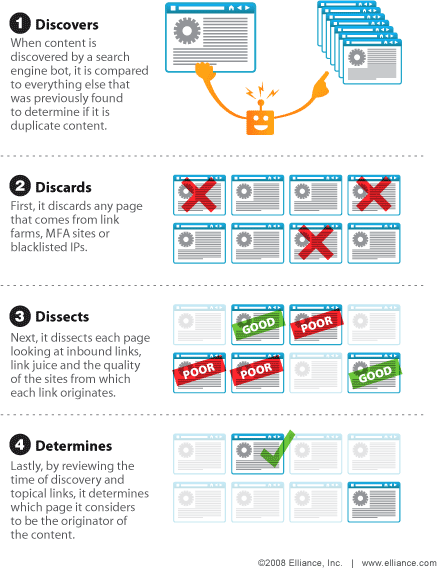
Da Google nicht bereits im voraus wissen kann, ob eine Seite Duplicate Content enthält, wird sie zunächst ganz normal gecrawlt und indexiert. Ungeachtet dessen, dass der komplette Vorgang der Indexierung von doppelten Inhalten für Google Zeitverschwendung ist und unnötige Ressourcen frisst, wird trotzdem geprüft, ob der Ursprung ermittelt werden kann.
Handelt es sich um mehrere gleiche oder ähnliche Inhalte, die nur auf der eigenen Seite vorkommen, dann wird ermittelt, ob es sich dabei um notwendige Duplizierungen handelt oder manipulative Maßnahmen wie bspw. Spam. Bei notwendigen Duplizierungen (bspw. sich wiederholende rechtliche Angaben in einem Webshop) wirken sich diese nicht negativ auf das Ranking aus – handelt es sich hingegen um Spammy-Keyword-Content, verlieren im günstigsten Fall einfach nur alle betroffenen Seiten an Relevanz und versinken in den unendlichen Weiten des Goooooooooogle. Im schlimmsten Fall, nämlich dann wenn die Vermutung naheliegt, dass permanent und bewusst duplizierte Inhalte verbreitet werden, droht sogar die Abstrafung und Zurücksetzung im Ranking! Ähnlich verhält es sich auch dann, wenn festgestellt wird, dass der Content von einer anderen Seite kopiert oder „geklaut“ wurde. Die Folge ist eine unmittelbare Herabstufung im Ranking oder gar Abstrafung, wenn es häufiger vorkommt.
Wie wird Duplicate Content von Google bewertet?
Manchmal lässt sich Duplicate Content nicht vermeiden oder ist sogar fester Bestandteil eines Projekts, in welchem sich einzelne Textabschnitte wiederholen. So z.B. Inhalte, die jedem Nutzer auf jeder Seite unkompliziert zur Verfügung stehen sollen oder rechtlich relevante Texte (Terms & Conditions), die bei verschiedenen Angeboten wiederholt werden müssen.
Genau diesem Thema hat sich Matt Cutts in folgendem Video angenommen und beantwortet damit die Frage: Ist Duplicate Content wirklich so schlimm? Welche Folgen kann es auf das Ranking bei Google haben?
[dsgvo-youtube url=“https://www.youtube.com/watch?v=Vi-wkEeOKxM“][/dsgvo-youtube]Kurz und knapp auf den Punkt gebracht: [blockquote]Duplicate Content ist nicht grundsätzlich etwas Böses oder Schlimmes. Nur wer Duplicate Content als Manipulationsinstrument nutzt, muss eine Abstrafung von Google fürchten.[/blockquote]
Häufige Ursachen für Duplicate Content
Das duplizieren von Inhalten geschieht sehr häufig, ohne dass man es als Seitenbetreiber richtig wahrnimmt. Zum Einen können technische Aspekte die Ursache für Duplicate Content sein, zum anderen aber auch inhaltliche Vorgänge, die als selbstverständlich erachtet werden:
- Ihre Homepage ist mit und ohne www erreichbar
Beispiel: https://ihredomain.de & http://ihredomain.de
- Ihre Homepage ist per http und https erreichbar
Beispiel: https://ihredomain.de & https://www.ihredomain.de - Eine alte Seite wird durch eine neue Seite ersetzt
Die alte Seite ist noch im Index der Suchmaschine und hat sich evtl. ein gutes Ranking aufgebaut, die neue Seite bietet nun jedoch dieselben Inhalte unter einem neuen Permalink (gleiche Domain, jedoch neue Link-Struktur). - Domain-Umzug
Sämtliche Seiten sind noch unter der alten Domain erreichbar und bei der Suchmaschine indexiert und die neue Domain liefert nun dieselben Inhalte unter einer völlig neuen URL. Bei einem Domain-Umzug sollte für die alte URL sofort eine Weiterleitung auf die neue URL eingerichtet werden. - Kategorien, Tags, Archive, Paginierung
Ein und dieselbe Seite ist sowohl direkt erreichbar, als auch über verschiedene Kategorien, Tags, Seitenzahlen, usw. (Beispiel: /duplicate-content/ – /seo/duplicate-content/ – /2/duplicate-content). Mitunter ein häfiges Problem bei den beliebten Tag-Clouds. - Print-Versionen von Seiteninhalten
Wenn Sie Ihren Nutzern die Möglichkeit geben, Seiteninhalte auszudrucken (sei es nun über eine printfähige separate Seite oder ein PDF-Dokument), dann wird auch Google diese Version finden und evtl. als Duplicate Content einstufen. - Mobile Webseite mit identischem Inhalt
Wenn Sie für Nutzer von mobilen Endgeräten (Smartphone, Tablet) eine mobile Webseite ausliefern, dann sollten Sie dafür sorgen, dass Google das erkennen kann. Google verwendet für mobile Webseiten bzw. die mobile Suche einen speziellen Crawler / User-Agent, dieser sollte also immer auf die mobile Version der Webseite geleitet werden:
[dsgvo-youtube url=“https://www.youtube.com/watch?v=mY9h3G8Lv4k“][/dsgvo-youtube] - Unterschiedliche Sprachversionen einer Webseite
Viele Onlineshops und Webseiten von internationalen Unternehmen sind in unterschiedlichen Sprachen verfügbar, wobei sich die verfügbaren Inhalte (Produkte, Dienstleistungen und Beschreibungen) meist nur minimal unterscheiden. So lange Google die geografische Ausrichtung der Seite feststellen kann, wird das Ranking nicht beeinflusst – denn je nach Land wird immer die passende Sprachversion der Webseite als Suchtreffer ausgeliefert. Bei internationalen, mehrsprachigen Seiten sollte die geografische Ausrichtung der Seite stets mitgeteilt werden (z.B. mittels hreflang-Attribut). Matt Cutts erklärt, wie Google mit Duplicate Content auf verschiedenen TLDs (Top-Level-Domains) umgeht:[dsgvo-youtube url=“https://www.youtube.com/watch?v=Ets7nHOV1Yo“][/dsgvo-youtube] - URL-Parameter und Session-IDs
Werden gerne dazu verwendet, die Herkunft und das Verhalten der Webseiten-Besucher zu tracken (?sid=82). Durch diese Tracking-Parameter entstehen für die Suchmaschine unterschiedliche URL’s, die denselben Inhalt und somit Duplicate Content ausliefern. - Paginierung (Seitennummerierung) von Kommentaren
Viele Content-Management-Systeme bietet die Möglichkeit, ab einer bestimmten Anzahl von Kommentaren eine Trennung auf mehrere Seiten vorzunehmen. So entstehen für die Suchmaschine neue URL’s (?comments-1, &comments-2, …) mit Duplicate Content. - Mehrere Domains, die denselben Inhalt veröffentlichen
Es kommt vor, dass Seiteninhalte (bewusst) auf mehreren Webseiten veröffentlicht werden. Wenn auf diesen Webseiten keine Quellangabe mit entsprechender Verlinkung erfolgt, kann die Suchmaschine nicht mehr erkennen, woher das Original stammt. Evtl. ranken diese Seiten dann für denselben Inhalt besser, als Ihre eigene Webseite. - Groß- und Kleinschreibung in URL’s
Bei URL’s sollte nur die Kleinschreibung verwendet werden, um eine mehrfache Indexierung zu vermeiden (bspw. /duplicate-content/ und /Duplicate-Content/). - Identische oder sehr ähnliche Produktbeschreibungen
Ein häufiges Problem bei Webshops, die Hersteller-Artikel-Beschreibungen übernehmen oder bei vielen ähnlichen Produkten (bspw. Farbvarianten) automatisiert dieselben Beschreibungen platzieren. Hier unterscheiden sich dann sowohl Inhalt, als auch META-Description und Seitentitel nur noch minimal. Besonders bei der Verwendung von Affiliate-Feeds oder Hersteller Produktbeschreibungen besteht das Problem, dass ein und derselbe Content auf hunderten von E-Commerce Seiten veröffentlich wird und man sich nicht mehr abheben kann – worin soll da noch ein Mehrwert liegen? Es gibt dazu ein sehr schönes Video von Google, in dem Matt Cutts den Sachverhalt erklärt:[dsgvo-youtube url=“https://www.youtube.com/watch?v=z07IfCtYbLw“][/dsgvo-youtube]
Es gibt darüber hinaus sicherlich noch weitere Ursachen für Duplicate Content, die jedoch kaum ins Gewicht fallen. Ein Punkt den ich nicht aufgeführt habe, den ich aber auch für selbstverständlich erachte: duplizieren Sie niemals wissentlich Inhalte in dem Irrglauben, dass die Seite dann besser gefunden wird! Genau das Gegenteil wird der Fall sein!
Duplicate Content Analyse
Es gibt mehrere Möglichkeiten die eigene Webseite auf Duplicate Content zu überprüfen. Der einfachste Weg ist die Nutzung von kostenlosen SEO Tools, die ich Ihnen im Folgenden vorstelle:
Internen Duplicate Content finden
Interner Duplicate Content entsteht, wenn identische oder ähnliche Inhalte innerhalb einer Domain ausgeliefert werden. Dieses Problem tritt besonders häufig bei Content-Management-Systemen wie WordPress auf, wenn bspw. Seiten oder Beiträge unterschiedlichen Kategorien zugeordnet oder mit Tags versehen sind.
Die häufigsten Gründe für internen Duplicate Content sind:
- Webseite ist mit und ohne www erreichbar
- Webseite ist per http und https erreichbar
- Archiv- und Kategorie-Seiten
- Übersichtsseiten für Filter oder Tags
- interne Suchergebnisseiten
- Seiten oder Beiträge, die mehreren Kategorien und/oder Tags zugeordnet sind
- Paginierung (Seitennummerierung) z.B. von Kommentaren
- URL-Parameter und Session-IDs
- Print-Versionen von Seiteninhalten
- Identische oder sehr ähnliche Produktbeschreibungen
- Mobile Webseite mit identischem Inhalt
Internen Duplicate Content finden mit Siteliner:
Ein sehr nützliches und kostenloses Tool, um internen Duplicate Content auf der eigenen Webseite zu finden, ist Siteliner. Mit Hilfe von Siteliner können Sie Ihre gesamte Webseite auf doppelte Inhalte überprüfen und erhalten eine detaillierte Auflistung der einzelnen Seiten mit Angaben zur prozentualen Übereinstimmung der Inhalte (übereinstimmende Wörter, prozentuale Übereinstimmung der Seiteninhalte, Anzahl der Seiten mit ähnlichem Inhalt, Relevanz der Seite für Suchmaschinen).
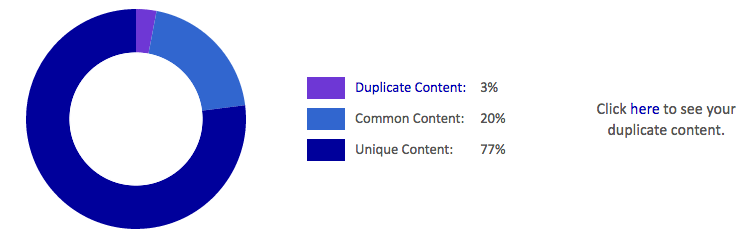
Seiten mit einer hohen Übereinstimmung der Inhalte sollten dringend näher betrachtet und analysiert werden. Meist handelt es sich dabei um für Suchmaschinen irrelevante Kategorie oder Archiv-Seiten, die man gefahrlos mittels „noindex, follow“ in den META-Daten von der Indexierung ausschließen kann.
Externen Duplicate Content finden
Externer Duplicate Content entsteht immer dann, wenn derselbe Inhalt auf verschiedenen Domains zu finden ist. Dies können eigene Webprojekte sein, auf denen zum Teil dieselben Inhalte veröffentlicht werden oder auch fremde Webseite wie bspw. Presseportale, Nachrichtendienste, Foren, RSS oder News-Aggregatoren usw..
Die häufigsten Gründe für externen Duplicate Content sind:
- Webprojekte, auf denen teils ähnliche oder identische Inhalte veröffentlicht werden
- Content-Klau bzw. Content-Diebstahl
- Content-Scraping (Scraped content)
- Verbreitung / Veröffentlichung von Pressemitteilungen
- Übernahme von Hersteller Produkt- oder Artikelbeschreibungen
- Veröffentlichen der eigenen Inhalte auf Newsportalen oder in Foren
- Content-Einspielung von Newslettern oder über RSS-Feeds
Externen Duplicate Content finden mit Copyscape
Copyscape ist das Pendant zu Siteliner und spezialisiert auf die Suche nach Kopien und Plagiaten im Internet. Nach Eingabe der eigenen URL durchforstet das Tool seinen Datenbestand und externe Datenquellen nach ähnlichen oder identischen Inhalten und gibt für die Suchtreffer anschließend einen Textausschnitt zusammen mit den Webseiten aus, auf denen die Duplikate gefunden wurden.
Duplicate Content Analyse mit der Google Suche
Eine weitere Möglichkeit der Duplicate Content Analyse ist eine Abfrage der Google-Suche auf markante Seiteninhalte, denn damit finden Sie sowohl interne als auch externe doppelte Inhalte. Kopieren Sie dazu einen Textausschnitt von Ihrer Website (von dem Sie wissen, dass dieser auf keiner anderen Webseite vorkommen dürfte) und fügen Sie diesen mit Anführungszeichen (am Anfang und am Ende des Satzes) in das Suchfeld bei Google ein. Der Textausschnitt sollte nicht mehr als 32 Wörter beinhalten, da Suchanfragen bei Google auf 32 Wörter begrenzt sind. Wenn es mehr sind, kürzt Google automatisch.
Im Idealfall, wenn also kein Duplicate Content gefunden wird, sieht das Suchergebnis so aus:
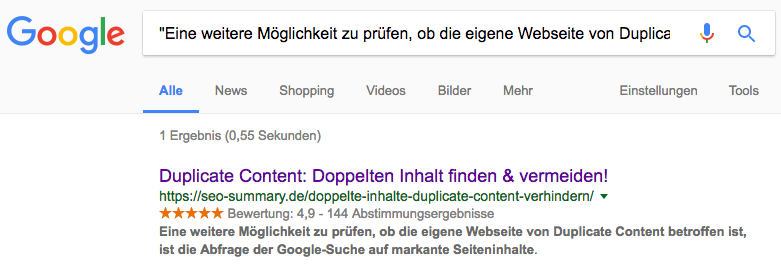
Wenn Sie mehr als einen Suchtreffer erhalten, dann gibt es Duplicate Content. Die externen Duplikate erkennen Sie ganz einfach daran, dass unterschiedliche Webseiten (Domains) aufgelistet werden, auf denen derselbe Textausschnit gefunden wurde. Die internen Duplikate hingegen versucht Google gleich herauszufiltern und zeigt Ihnen den „Fund“ anstelle der Suchtreffer in der Regel auch anhand folgender Meldung:
[blockquote source=“DC-Hinweis in den Suchtreffern von Google“]Damit Sie nur die relevantesten Ergebnisse erhalten, wurden einige Einträge ausgelassen, die den 2 angezeigten Treffern sehr ähnlich sind. Sie können bei Bedarf die Suche unter Einbeziehung der übersprungenen Ergebnisse wiederholen. [/blockquote]Lassen Sie sich in einem solchen Fall die vermeintlichen doppelten Inhalte anzeigen (Suche wiederholen) und überprüfen Sie, ob es Ihre eigene Webseite betrifft oder gar ungewollt Plagiate Ihres Seiteinhalts im Netz auftauchen.
Duplicate Content vermeiden
1.) Domain-Umleitung mit ModRewrite in der .htaccess
Mit folgendem Eintrag in der .htaccess Datei (im Root Verzeichnis Ihres Webservers) können Sie die Domain ohne www auf die Domain mit www umleiten:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^beispiel.de
RewriteRule ^(.*)$ https://beispiel.de$1 [R=301,L]
Das Ganze geht natürlich auch anders herum:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.beispiel.de
RewriteRule ^(.*)$ http://beispiel.de$1 [R=301,L]
2.) Dauerhafte, serverseitige Weiterleitung mit 301 Redirect per .htaccess
Eine dauerhafte Weiterleitung sollte nur dann eingesetzt werden, wenn Sie eine alte (nichts mehr existierende) Datei auf eine neue umleiten möchten oder auch gleich eine ganze Domain. Der große Vorteil bei einem 301 Redirect liegt darin, dass der PageRank mit auf das neue Ziel übertragen wird! Die Einstellung erfolgt wiederum über die .htaccess Datei im Root-Verzeichnis Ihres Webservers.
Wenn Sie eine einzelne Datei umleiten möchten:
RedirectPermanent /seite-alt.html https://ihredomain.de/seite-neu.html
Wenn Sie eine ganze Domain umleiten möchten:
RedirectPermanent / https://domain-neu.de
3.) 301 Redirect mit der Funktion header() in PHP
Alternativ zur permanenten Weiterleitung in der .htaccess gibt es auch die Möglichkeit, folgenden Verweis direkt in der HTML oder PHP Datei zu platzieren:
4.) Canonical Tags / rel=canonical
Canonical Tags sind eine sehr gute Möglichkeit, um verschiedene Seiten mit sehr ähnlichen oder identischen Inhalten zusammenzufassen, indem man den Suchmaschinen mitteilt, welche URL bevorzugt wird bzw. repräsentativ ist. Ich zitiere an dieser Stelle gerne Google, die es kurz und knapp auf den Punkt bringen: „Eine kanonische Seite ist die bevorzugte Version mehrerer Seiten mit ähnlichen Inhalten.″
Der Canonical Tag wird im <head> Bereich der Seite wie folgt platziert:
Eine sehr ausführliche Erklärung zu Canonical Tags sowie leicht verständliche Beispiele, wie man diese am besten einsetzt, finden Sie direkt bei Google. Für Webshops oder Druckversionen von Seiten ist rel=canonical meist die beste und effektivste Möglichkeit, um Duplicate Content zu verhindern.
5.) noindex Hinweis in den META Tags
Über einen noindex Vermerk in den META-Tags können Sie den Suchmaschinen mitteilen, dass die Seite nicht indexiert werden soll. Der Rest ist selbsterklärend: was nicht indexiert wird, kann auch keinen Dupliacte Content verursachen.
Der folgende Eintrag sorgt dafür, dass die Seite nicht indexiert wird, aber dennoch ohne Einschränkung von der Suchmaschine gecrawlt werden kann (empfohlen):
Wenn Die Seite hingegeben weder indexiert noch darauf befindliche Verweise auf andere Seiten verfolgt werden sollen, dann kommt das nofollow-Attribut zum Einsatz:
6.) Keine Inhalte kopieren, keine Seiten duplizieren, keine Textbausteine!
Seien Sie kreativ und nehmen Sie sich Zeit für die Inhalte Ihrer Seite! Verzichten Sie darauf, Inhalte von anderen Seiten zu kopieren und setzen Sie auch keine identischen oder ähnlichen Textbausteine ein. Und wenn eine Seite noch nicht fertig ist, dann verzichten Sie bitte auf sogenannte „Platzhalter“ oder schließen Sie diese zumindex mit „noindex“ von der Indexierung aus, bis Sie fertiggestellt ist. Und am schlimmsten: bedienen Sie sich nicht einfach an den Inhalten anderer Seiten, sondern verwenden Sie dabei immer eine Quellangabe.
7.) URL-Parameter konfigurieren über die Google Search Console
 Die Google Search Console (ehem. Webmaster Tools) beinhaltet eine umfangreiche Werkzeug-Sammlung für Webmaster und ist die beste (kostenfreie) Möglichkeit, den Überblick über die Indexierung der eigenen Webseite zu behalten. Sie können hier unter anderem mitteilen, wie die Domain indexiert werden soll (mit oder ohne www), sehen sofort wenn Probleme auftreten und können festlegen, wie mit verschiedenen URL-Parametern umgegangen werden soll. Aber Vorsicht: Falsch konfigurierte Parameter können bewirken, dass Seiten Ihrer Website aus unserem Index entfernt werden, daher sollten Sie dieses Tool nur bei Bedarf einsetzen.
Die Google Search Console (ehem. Webmaster Tools) beinhaltet eine umfangreiche Werkzeug-Sammlung für Webmaster und ist die beste (kostenfreie) Möglichkeit, den Überblick über die Indexierung der eigenen Webseite zu behalten. Sie können hier unter anderem mitteilen, wie die Domain indexiert werden soll (mit oder ohne www), sehen sofort wenn Probleme auftreten und können festlegen, wie mit verschiedenen URL-Parametern umgegangen werden soll. Aber Vorsicht: Falsch konfigurierte Parameter können bewirken, dass Seiten Ihrer Website aus unserem Index entfernt werden, daher sollten Sie dieses Tool nur bei Bedarf einsetzen.
8.) Sprachversion definieren (rel=“alternate“ hreflang=“x“)
Unterschiedliche Sprachversionen einer Webseite – speziell bei Onlineshops mit marginalen Unterschieden bei Produkten und Beschreibungen – lassen sich über das rel=“alternate“ hreflang=“x“ Link-Attribut definieren. Dieses Attribut wird im HTML-Headerder Webseite wie folgt definiert (deutsch / englisch / spanisch):
Weitere Informationen über das hreflang-Attribut finden Sie hier.
9.) Halten Sie sich an die Empfehlungen von Google
Google selbst stellt Webmastern diverse Hilfestellungen zur Verfügung, um Duplicate Content zu vermeiden. Unter anderem empfiehlt Google:
- Verwenden Sie 301-Weiterleitungen
- Achten Sie auf Konsistenz bei der internen Verlinkung
- Syndizieren Sie sorgfältig
- Minimieren Sie wiederkehrende Textbausteine
- Vermeiden Sie die Veröffentlichung von Platzhaltern
- Analysieren Sie Ihr Content Management-System
- Minimieren Sie ähnlichen Content
- Nutzen Sie die Google Search Console
Details dazu finden Sie in der Google Search Console-Hilfe
Welche Seiten sollten nicht indexiert werden?
Im Grunde genommen muss jeder für sich selbst entscheiden, inwieweit die Indexierung der eigenen Webseite zugelassen werden soll. Empfehlenswert ist es jedoch, folgende Inhalte auszuschließen, da diese in der Regel zwar der Navgiation dienlich und für den Nutzer interessant sein können, nicht aber für Suchmaschinen:
- Alle Seiten, die identischen oder sehr ähnlichen Inhalt liefern.
Beispiel: socken-blau.html, socken-grün.html, socken-gelb.html - Kategorien und Tags, die auf mehreren Ebenen dieselben Inhalte ausliefern
Beispiel: …/socken/, …/socken/blau/, …/socken/blau/strick/ - Seitenzahlen und Archive, die dieselben Inhalte ausliefern
Beispiel: …/sockel-blau.htm, …/archiv/1/sockel-blau.htm - Affiliate URLs / Session IDs / Tracking Parameter
Beispiel: ?partner_id=123, ?session_id=123, ?tracking_id=123 - Suchfilter bzw. Ergebnisseiten mit Suchparametern
Beispiel: &ort=stuttgart, &farbe=blau, &ort=stuttgart?farbe=blau
Die einfachste Möglichkeit, diese Seiten von der Indexierung auszuschließen, ist die Definition von URL Parametern in der Google Search Console und/oder die noindex-Angabe im Header.
Was Sie nicht tun sollten, um Duplicate Content zu vermeiden:
Verbieten Sie den Suchmaschinen nicht das crawlen! Wenn Sie bspw. Seiten oder Bereiche über die robots.txt von der Indexierung ausschließen, dann verbieten Sie der Suchmaschine damit auch diese Seiten zu besuchen und sich selbst einen Überblick zu verschaffen. Google, Bing & Co. sind durchaus dazu in der Lage, die Relevanz einzelner Seiten und damit auch ähnlicher Inhalte korrekt zu bewerten und lernen auch täglich dazu – das klappt jedoch nicht, wenn Sie gleich gänzlich den Riegel vorschieben. Insbesondere Google rät ausdrücklich davon ab, die robots.txt zur Vermeidung von Duplicate Content zu nutzen.
Auch das „URLs entfernen“ Tool in der Google Search Console ist zur Vermeidung von Duplicate Content gänzlich ungeeignet, denn es beseitigt nicht die Ursache sondern führt lediglich zu einer vorübergehenden Entfernung der Seite aus den Suchergebnissen.
Fazit
Die Problematik Duplicate Content bzw. doppelte Inhalte trifft sehr viele Webseitenbetreiber und ich kann Ihnen nur empfehlen, sich eingehend damit zu beschäftigen, da dies unmittelbare Auswirkungen auf Ihre Platzierung und Sichtbarkeit in den Suchmaschinen haben kann.
Im Allgemeinen sollte man sich darüber im Klaren sein, dass Duplicate Content nicht grundsätzlich schlecht ist – denn Google ist durchaus dazu in der Lange, guten von schlechtem (Spammy) Content zu unterscheiden. Wenn Sie meinen Artikel aufmerksam verfolgt haben, dann wissen Sie jetzt, wie Sie die häufigsten Ursachen erkennen und beseitigen können und an welchen Stellen Sie dabei ansetzen müssen. Viel Erfolg!